GitHub - Zeta36/chess-alpha-zero: Chess reinforcement learning by AlphaGo Zero methods.
Por um escritor misterioso
Last updated 14 julho 2024

Chess reinforcement learning by AlphaGo Zero methods. - GitHub - Zeta36/chess-alpha-zero: Chess reinforcement learning by AlphaGo Zero methods.

ansev-0 · GitHub

Policy and value heads are from AlphaGo Zero, not Alpha Zero

IIvec · GitHub
First good results · Issue #13 · Zeta36/chess-alpha-zero · GitHub

Frontiers Learning to Play the Chess Variant Crazyhouse Above
AlphaZero's pipeline. Self-play games' data are continuously
alphago · GitHub Topics · GitHub
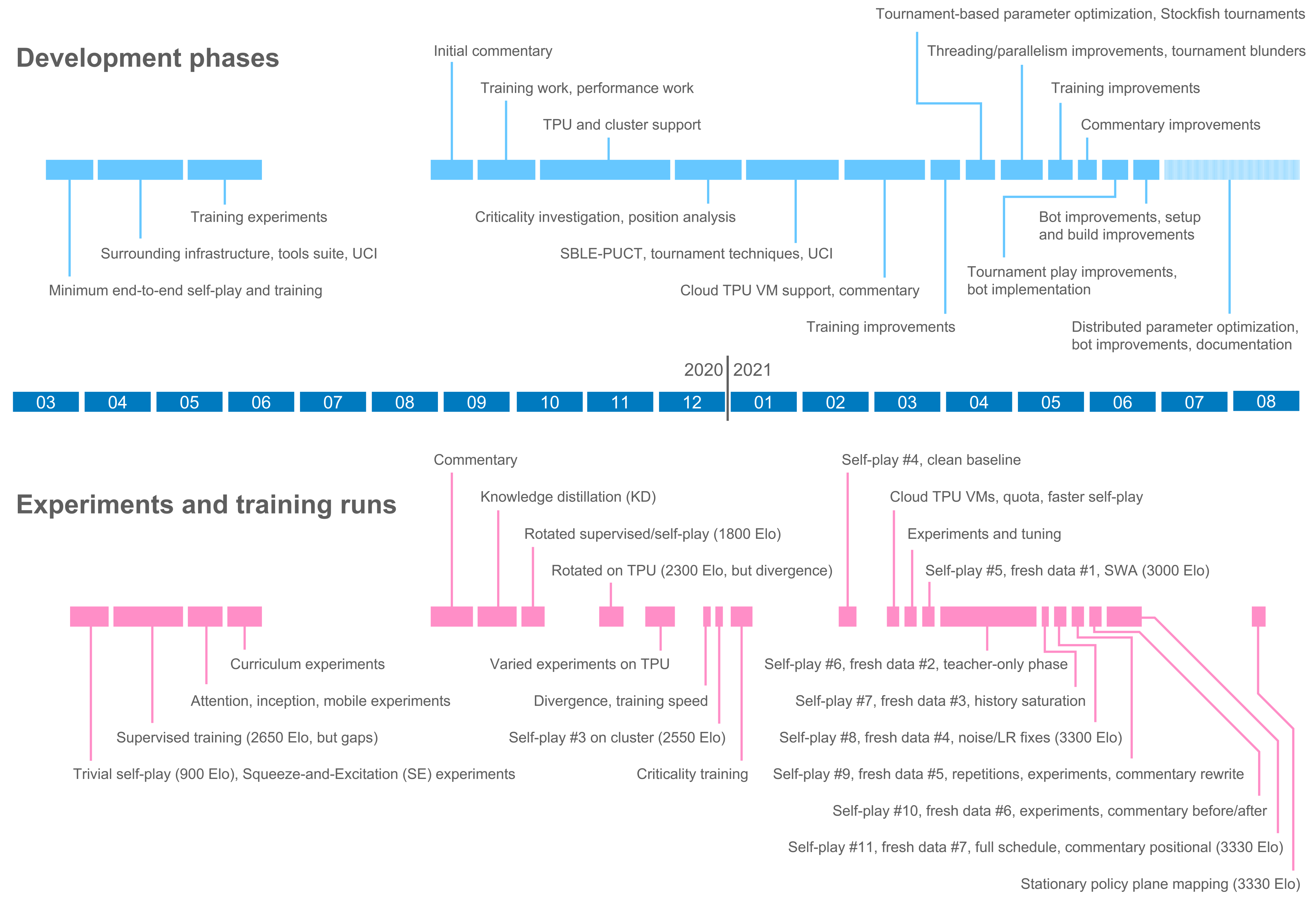
Development process

Is it possible to train the value output in a supervised (or even
Recomendado para você
-
Xadrez Alphazero Vs Stockfish, PDF, Chess14 julho 2024
-
 Quem joga muito xadrez tende a ficar mais inteligente?14 julho 2024
Quem joga muito xadrez tende a ficar mais inteligente?14 julho 2024 -
 Inteligência artificial do Google vira mestre em xadrez em 4 horas de treino - Olhar Digital14 julho 2024
Inteligência artificial do Google vira mestre em xadrez em 4 horas de treino - Olhar Digital14 julho 2024 -
 Revista de Xadrez New In Chess 2019-8 Magnus Carlsen Observe as Fotos14 julho 2024
Revista de Xadrez New In Chess 2019-8 Magnus Carlsen Observe as Fotos14 julho 2024 -
 AlphaZero Queen's Indian Intro - Jan Gustafsson vídeo de xadrez14 julho 2024
AlphaZero Queen's Indian Intro - Jan Gustafsson vídeo de xadrez14 julho 2024 -
 IA do Google aprende sozinha a jogar xadrez e vence campeão mundial – Tecnoblog14 julho 2024
IA do Google aprende sozinha a jogar xadrez e vence campeão mundial – Tecnoblog14 julho 2024 -
 Hackeando o Xadrez com Decision Making Deep Reinforcement Learning, by Octavio Santiago, Data Hackers14 julho 2024
Hackeando o Xadrez com Decision Making Deep Reinforcement Learning, by Octavio Santiago, Data Hackers14 julho 2024 -
AlphaZero: Shedding new light on chess, shogi, and Go - Google14 julho 2024
-
 Creative' AlphaZero leads way for chess computers and, maybe14 julho 2024
Creative' AlphaZero leads way for chess computers and, maybe14 julho 2024 -
 E agora Google Alpha Zero, PERDEU A DAMA??? Partida de xadrez14 julho 2024
E agora Google Alpha Zero, PERDEU A DAMA??? Partida de xadrez14 julho 2024


você pode gostar
-
Venda de jogos da psp14 julho 2024
-
 BTMC Skins14 julho 2024
BTMC Skins14 julho 2024 -
 Used Honda Dio for sale in Palakkad. ID 231090 - Bikes4Sale14 julho 2024
Used Honda Dio for sale in Palakkad. ID 231090 - Bikes4Sale14 julho 2024 -
 How to login roblox account without email in hindi, sign in roblox in mobile14 julho 2024
How to login roblox account without email in hindi, sign in roblox in mobile14 julho 2024 -
 Red Bricks - LEGO DC Super-Villains Guide - IGN14 julho 2024
Red Bricks - LEGO DC Super-Villains Guide - IGN14 julho 2024 -
 Paris Saint-Germain T-Shirt Sergio Ramos PSG - Official Collection, White : : Sports & Outdoors14 julho 2024
Paris Saint-Germain T-Shirt Sergio Ramos PSG - Official Collection, White : : Sports & Outdoors14 julho 2024 -
 InuYasha Wiki InuYasha+BreezeWiki14 julho 2024
InuYasha Wiki InuYasha+BreezeWiki14 julho 2024 -
 Mobile game Universal KouKou Love Tap Blast brings Shrek, Po, and more14 julho 2024
Mobile game Universal KouKou Love Tap Blast brings Shrek, Po, and more14 julho 2024 -
 Rubik's Cube Competition: SCS Battle Room V Open for Early Registration14 julho 2024
Rubik's Cube Competition: SCS Battle Room V Open for Early Registration14 julho 2024 -
 Small Mountain Castle w. full interior - Survival base Minecraft Map14 julho 2024
Small Mountain Castle w. full interior - Survival base Minecraft Map14 julho 2024
